\(\displaystyle\inf_x\, e^{-x}\) is not attained for any\(x\in\R\)
an optimal value may not exist, eg,
\(\displaystyle\min_x\, -x^2\) has no minimizer (unbounded below)
global solution set (may be empty, may have many elements)
\[\argmin_x f(x) = \{\bar x\mid f(\bar x) \le f(x) \text{ for all } x\}\]
optimal values are unique even if an optimal point is not unique
Theorem 1 (Coercivity implies existence of minimizer) If \(f:\Rn\to\R\) is continuous and \(\lim_{\|x\|\to\infty}f(x)=\infty\) (coercive), then \(\min_x\, f(x)\) has a global minimizer.
implies that \(f(x^*+\Delta x) > f(x^*)\) for \(\Delta x\) small enough
(n>1) multivariable
Directional derivative
Restriction to a ray
restrict \(f:\Rn\to\R\) to the ray \(\{x+\alpha d\mid \alpha\in\R_+\}\): \[
\phi(\alpha) = f(x+\alpha d)
\qquad
\phi'(0) = \lim_{\alpha\to 0^+}\frac{\phi(\alpha)-\phi(0)}{\alpha}
\]
Definition 1 The directional derivative of \(f:\R^n\to\R\) at \(x\in\R^n\) in the direction \(d\in\R^n\) is \[
f'(x;d) = \lim_{α\to0^+}\frac{f(x+αd)-f(x)}{α}.
\]
partial derivatives are directional derivatives along each canonical basis vector \(e_i\): \[
\frac{\partial f}{\partial x_i}(x) = f'(x;e_i)
\quad\text{with}\quad
e_i(j) = \begin{cases} 1 & j=i\\ 0 & j\ne i\end{cases}
\]
Descent directions
A nonzero vector \(d\) is a descent direction of \(f\) at \(x\), ie,
\[
f(x+\alpha d) < f(x) \quad \forall \alpha \in (0, \epsilon) \text{ for some } \epsilon > 0
\qquad(1)\]
equivalently, the directional derivative is negative:
If \(f:\Rn\to\R\) is continuously differentiable (ie, differentiable at all \(x\) and \(\nabla f\) is continuous) the gradient of \(f\) at \(x\) is the vector \[
\nabla f(x)= \begin{bmatrix}
\frac{\partial f}{\partial x_1}(x)\\
\vdots\\
\frac{\partial f}{\partial x_n}(x)
\end{bmatrix} \in \Rn
\]
gradient and directional derivative related via
\[
f'(x;d) = \nabla f(x)\T d
\]
which gives
the rate of change of \(f\) at \(x\) in the direction \(d\)
(if \(\|d\|=1\)) the projection of \(\nabla f(x)\) onto \(d\): \(f'(x;d) \cdot d\)
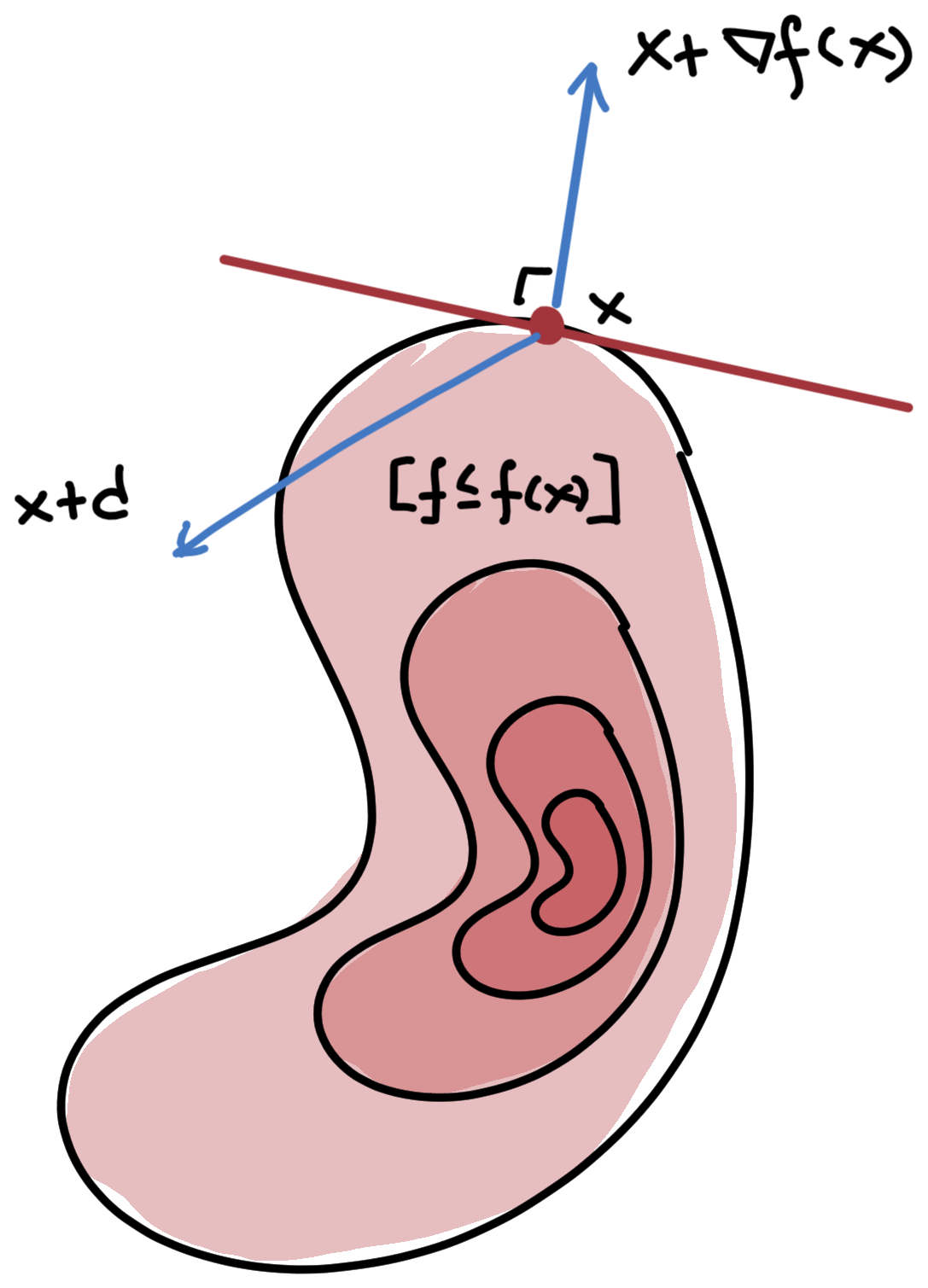
Definition 2 (Level set) The \(\alpha\)-level set of \(f\) is the set of points \(x\) where the function value is at most \(\alpha\):
\[
[f\leq \alpha] = \{x\mid f(x)\leq \alpha\}
\]
A direction \(d\) points “into” the level set \([f\leq f(x)]\) if \[f'(x;d) = \nabla f(x)\T d < 0\]
Linear approximation
If \(f:\Rn\to\R\) is differentiable at \(x\), then for any direction \(d\)\[
\begin{aligned}
f(x+d) &= f(x) + \nabla f(x)\T d + \omicron(\norm{d})\\
&= f(x) + f'(x;d) + \omicron(\norm{d})
\end{aligned}
\] The remainder\(\omicron:\R_+\to\R\) decays faster than \(\norm{d}\)
\[\lim_{α\to0+}\frac{\omicron(α)}{α}=0\]
1st-order conditions
Theorem 2 (Necessary first-order conditions) For \(f:\Rn\to\R\) differentiable, \(x^*\) is a local minimizer only if it is a stationary point: \[
\nabla f(x^*) = 0
\]
proof
up to first order, for any direction \(d\)\[
\begin{aligned}
f(x^*+\alpha d) - f(x^*) &= \nabla f(x^*)\T (\alpha d) + o(\alpha\|d\|)\\
&= \alpha f'(x^*;d) + o(\alpha\|d\|)
\end{aligned}
\]
because \(f\) is (locally) minimal at \(x^*\)\[
\begin{aligned}
0\le\lim_{\alpha\to 0^+}\frac{f(x^*+\alpha d) - f(x^*)}{\alpha} &= f'(x^*;d)=\nabla f(x^*)\T d
\end{aligned}
\]
because this holds for all \(d\), \(\nabla f(x^*)=0\)
\(x^*\) is a local minimizer only if\(\nabla f(x^*)=0\), ie, \[
0 = \nabla f(x^*) = Hx^* - c \quad\Longrightarrow\quad Hx^*=c
\]
if \(\Null(H)\ne\emptyset\) and \(b\in\range(H)\), then there exists \(x_0\) such that \(Hx_0=b\) and \[
\argmin_x\, f(x) = \{\, x_0 + z \mid z\in\Null(H)\,\}
\]
\(x^*\) is a least-squares solution if (and only if) it satisfies the normal equations\[
0 = \nabla f(x^*) = A\T Ax^* - A\T b \quad\Longleftrightarrow\quad A\T Ax^*=A\T b
\]