Regularized
Least Squares
CPSC 406 – Computational Optimization
Regularized least squares
\[
\def\argmin{\operatorname*{argmin}}
\def\Ball{\mathbf{B}}
\def\bmat#1{\begin{bmatrix}#1\end{bmatrix}}
\def\Diag{\mathbf{Diag}}
\def\half{\tfrac12}
\def\ip#1{\langle #1 \rangle}
\def\maxim{\mathop{\hbox{\rm maximize}}}
\def\maximize#1{\displaystyle\maxim_{#1}}
\def\minim{\mathop{\hbox{\rm minimize}}}
\def\minimize#1{\displaystyle\minim_{#1}}
\def\norm#1{\|#1\|}
\def\Null{{\mathbf{null}}}
\def\proj{\mathbf{proj}}
\def\R{\mathbb R}
\def\Rn{\R^n}
\def\rank{\mathbf{rank}}
\def\range{{\mathbf{range}}}
\def\span{{\mathbf{span}}}
\def\st{\hbox{\rm subject to}}
\def\T{^\intercal}
\def\textt#1{\quad\text{#1}\quad}
\def\trace{\mathbf{trace}}
\]
- competing objectives
- Tikhonov regularization (ridge regression)
- least-norm solutions
Multi-objective optimization
Many problems need to balance competing objectives, eg,
- choose \(x\) to minimize \(f_1(x)\) and \(f_2(x)\)
- can make \(f_1\) or \(f_2\) small, but not both
\(\xi^{(i)} := \{f_1(x^{(i)}),\ f_2(x^{(i)})\}\)
- \(\xi^{(1)}\) is not efficient
- \(\xi^{(3)}\) dominates \(\xi^{(1)}\)
- \(\xi^{(2)}\) is infeasible
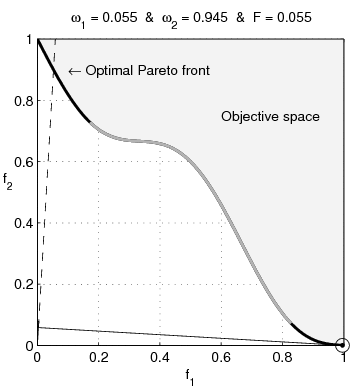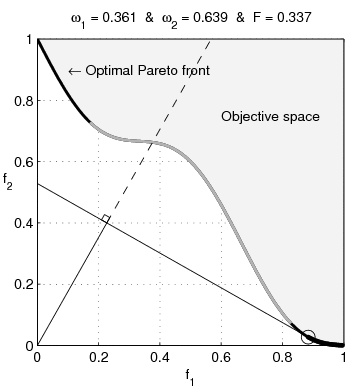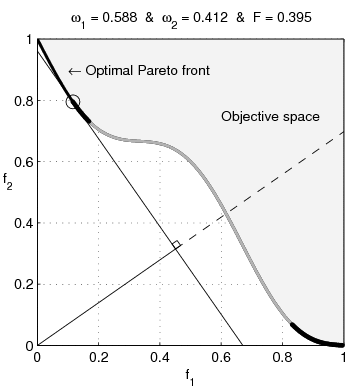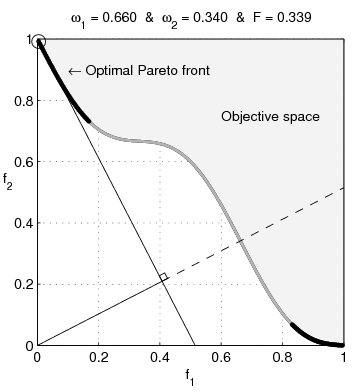
Weighted-sum objective
Common approach is to weight the sum of objectives: \[
\min_x \ \alpha_1 f_1(x) + \alpha_2 f_2(x)
\]
- penalty parameters \(\alpha_1, \alpha_2>0\)
- ratio \(\frac{\alpha_1}{\alpha_2}\) determines relative objective weights
- \(x^{(1)}\) solution for \(\alpha_1>\alpha_2\)
- \(x^{(2)}\) solution for \(\alpha_2>\alpha_1\)
Tikhonov regularization (aka Ridge regression)
\[
\min_x\ \tfrac12\|Ax - b\|^2 + \tfrac12\lambda\|Dx\|^2
\]
\(\|Dx\|^2\) is the regularization penalty (often \(D:=I\))
\(\lambda\) is the positive regularization parameter
equivalent expression for objective \[
\|Ax-b\|^2 + \lambda\|Dx\|^2
= \left\|\begin{bmatrix}A\\\sqrt\lambda D\end{bmatrix}x - \begin{bmatrix}b\\0\end{bmatrix}\right\|^2
\]
Normal equations (unique solution if \(D\) full rank) \[
(A\T A + \lambda D\T D)x = A\T b
\]
Example — signal denoising
observe noisy measurements \(y\) of a signal \[
b = \hat x + \eta \textt{where}
\left\{\begin{aligned}
x^\natural&\in\Rn\ \text{is true signal}
\\\eta &\in\R^n\ \text{is noise}
\end{aligned}
\right.
\]
![]()
Noisy smooth signal
Example — matrix notation
- Define the \((n-1)\times n\) finite difference matrix \[
D = \begin{bmatrix}
1 & -1 & \phantom-0 & \cdots & 0 & \phantom-0
\\0 &\phantom-1 & -1 & \cdots & 0 & \phantom-0
\\\vdots & \phantom-\vdots & \phantom-\vdots & \ddots & \vdots &\phantom-\vdots
\\0 & \phantom-0 & \phantom-0 & \cdots & 1 & -1
\end{bmatrix}
\quad\Longrightarrow\quad
\sum_{i=1}^{n-1}\|x_i-x_{i+1}\|^2 = \|Dx\|^2
\]
- least-squares objective \[
\|x - b\|^2 + \lambda\|Dx\|^2
= \left\|\begin{bmatrix}I\\\sqrt\gamma D\end{bmatrix}x - \begin{bmatrix}b\\0\end{bmatrix}\right\|^2
\]
- Normal equations \[
(I + \gamma D\T D)x = b
\]
Sparse matrices
\(D\) is sparse: only \(2n-2\) nonzero entries (2 per row)
using SparseArrays: spdiagm
finiteDiff(n) = spdiagm(0 => ones(n), +1 => -ones(n-1))[1:n-1,:]
finiteDiff(4)
3×4 SparseArrays.SparseMatrixCSC{Float64, Int64} with 6 stored entries:
1.0 -1.0 ⋅ ⋅
⋅ 1.0 -1.0 ⋅
⋅ ⋅ 1.0 -1.0






{kind=link}