using ForwardDiff
f(x) = (1 - x[1])^2 + 100*(x[2] - x[1]^2)^2
∇f(x) = ForwardDiff.gradient(f, x)
x = [1.0, 1.0]
@show ∇f(x);∇f(x) = [-0.0, 0.0]CPSC 406 – Computational Optimization
\[ \min_x\, f(x) \quad\text{where}\quad f:\Rn\to\R \]
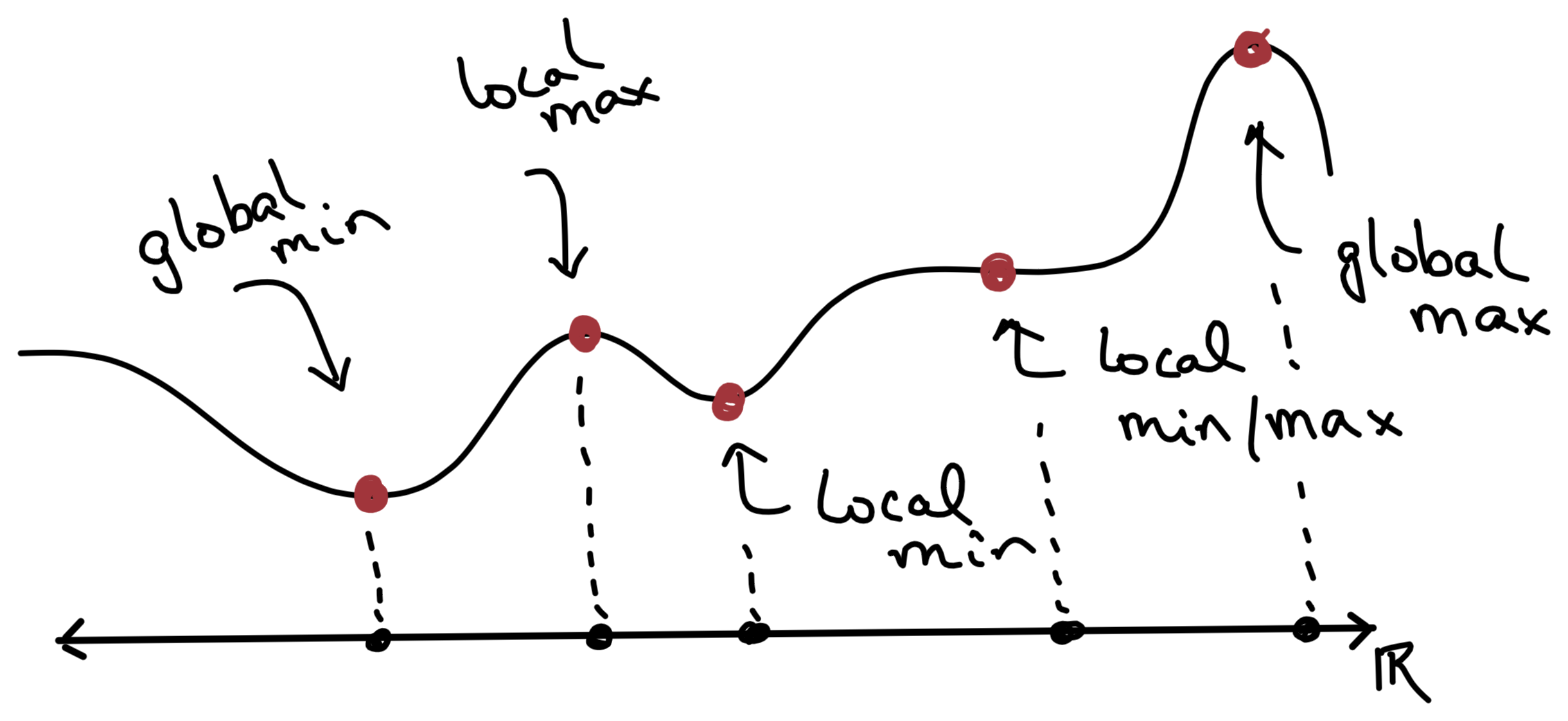
\(x^*\in\Rn\) is a
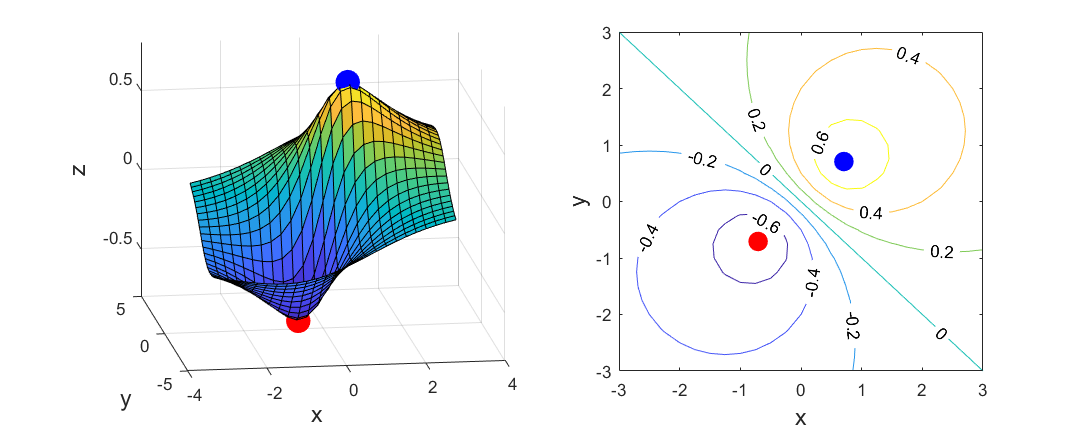
\[ \min_{x\in\R^2}\, \frac{x_1+x_2}{x_1^2+x_2^2+1} \]
Definition 2 (Level set) The \(\alpha\)-level set of \(f\) is the set of points \(x\) where the function value is at most \(\alpha\):
\[ [f\leq \alpha] = \{x\mid f(x)\leq \alpha\} \]
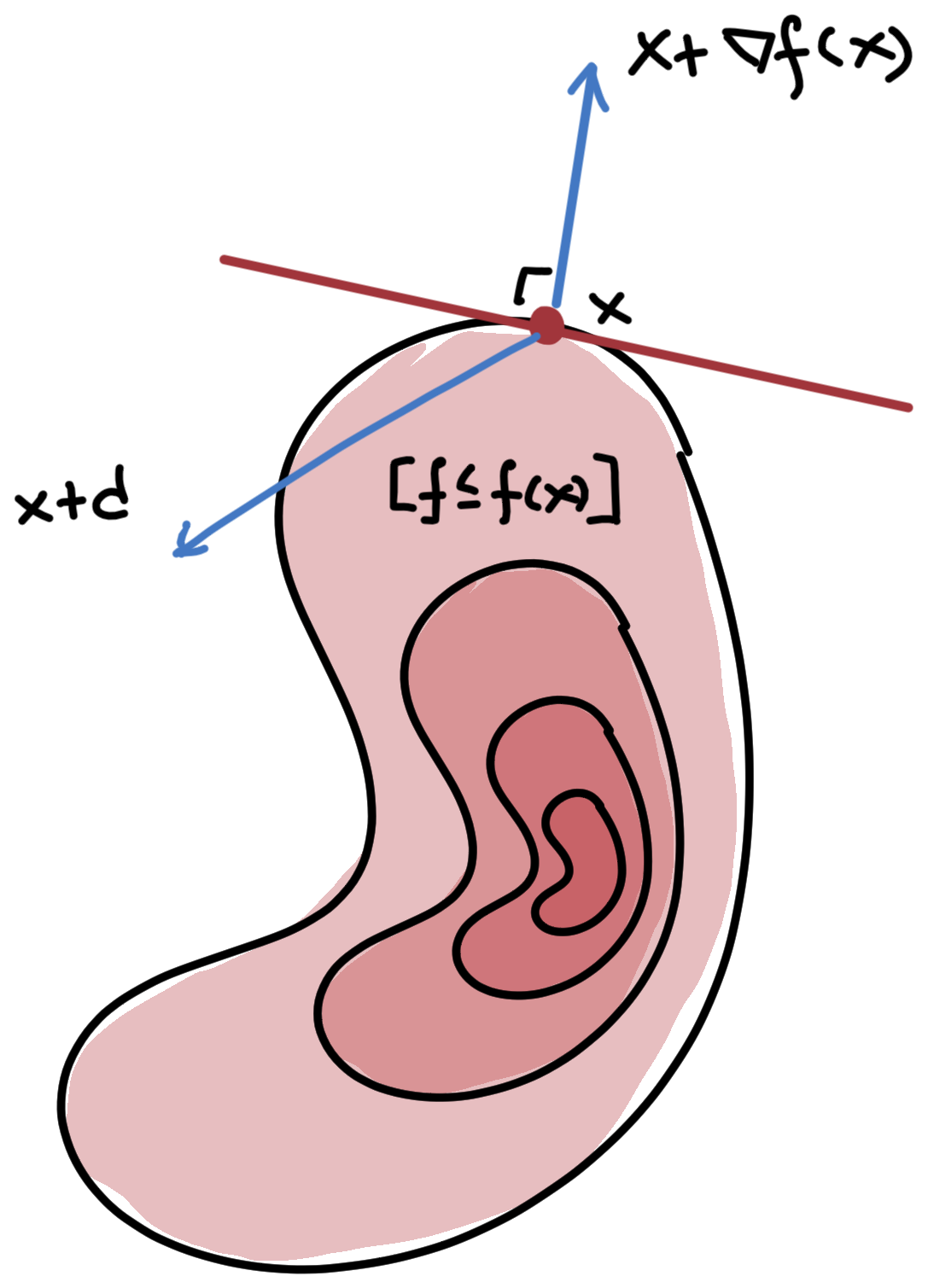
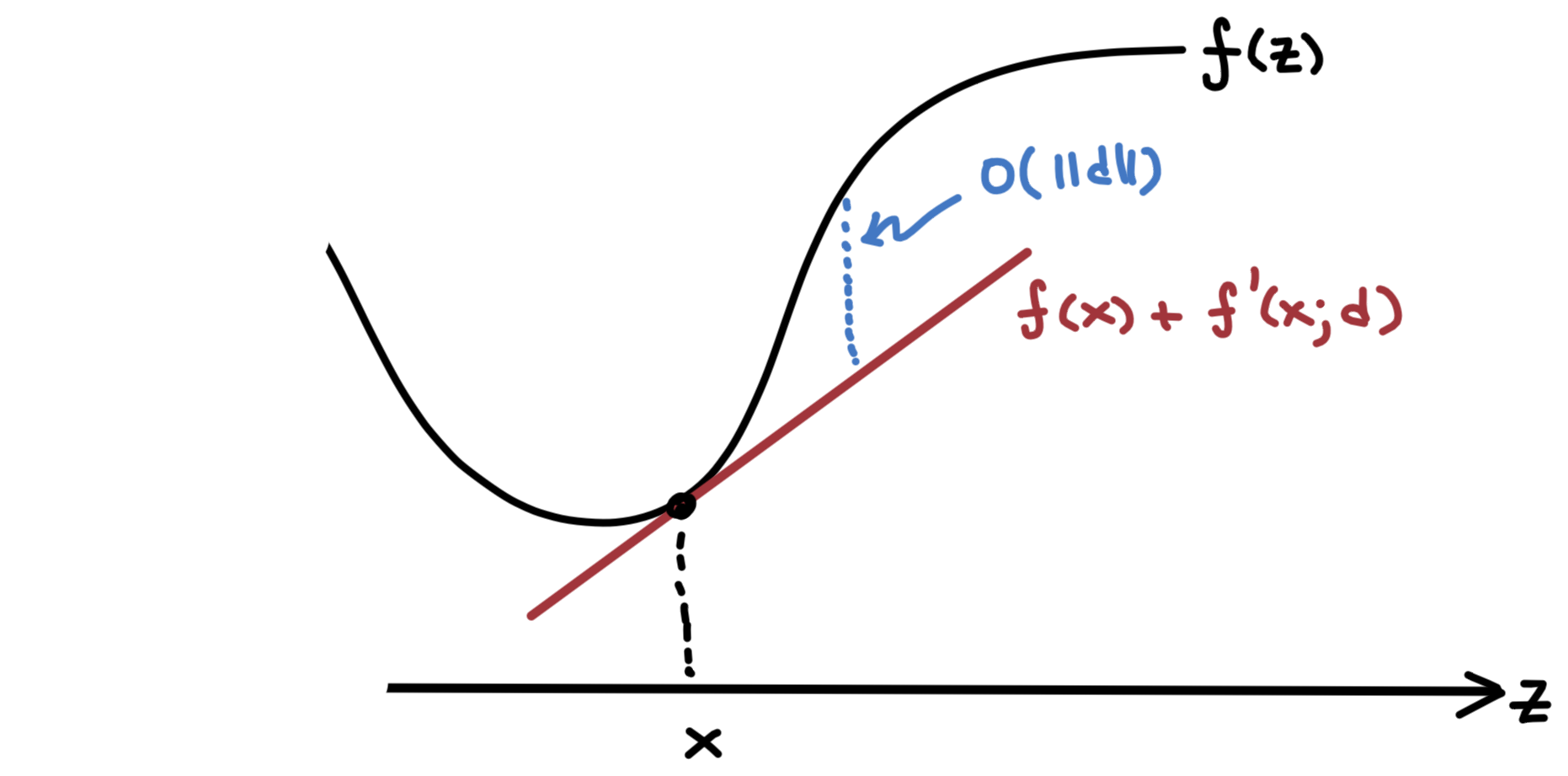
\[ \begin{aligned} f(x+d) = f(x) + \nabla f(x)\T d + \omicron(\norm{d}) = f(x) + f'(x;d) + \omicron(\norm{d}) \end{aligned} \]
\[\lim_{α\to0+}\frac{\omicron(α)}{α}=0\]