{kind=link}
using SparseArrays: spdiagm
finiteDiff(n) = spdiagm(0 => ones(n), +1 => -ones(n-1))[1:n-1,:]
finiteDiff(4)3×4 SparseArrays.SparseMatrixCSC{Float64, Int64} with 6 stored entries:
1.0 -1.0 ⋅ ⋅
⋅ 1.0 -1.0 ⋅
⋅ ⋅ 1.0 -1.0CPSC 406 – Computational Optimization
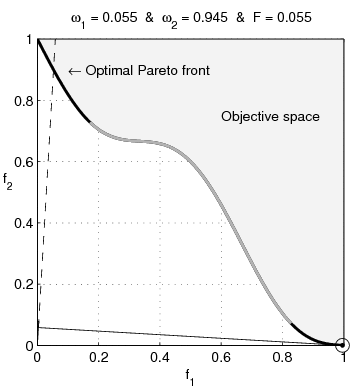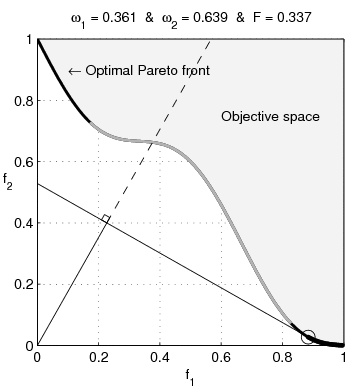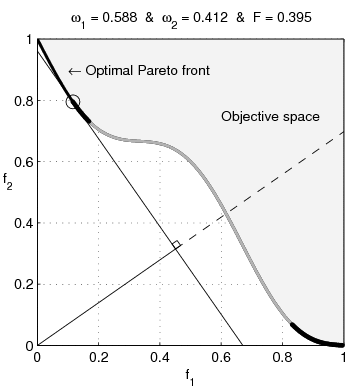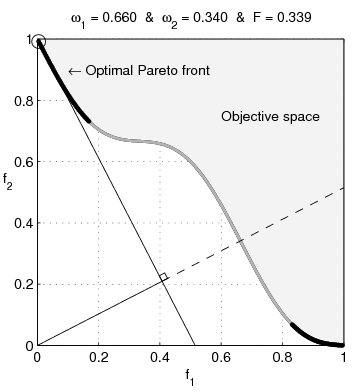
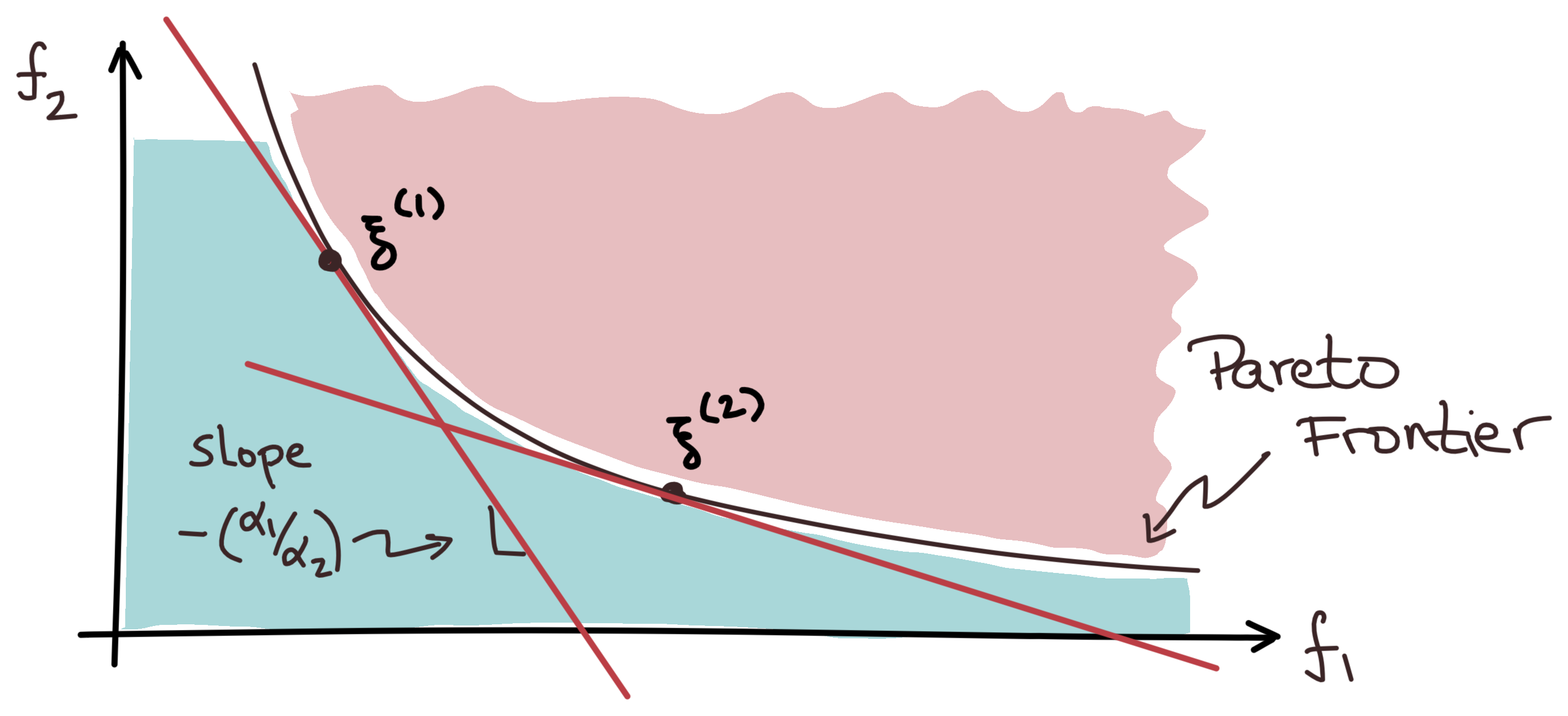
Many problems need to balance competing objectives, eg,
\[ x^{*} = \argmin_x f_1(x) \quad\Longrightarrow\quad f_1(x^{*}) \leq f_2(x^{*}) \]
\(\xi^{(i)} := \{f_1(x^{(i)}),\ f_2(x^{(i)})\}\)
Common approach is to weight the sum of objectives: \[ \min_x \ \alpha_1 f_1(x) + \alpha_2 f_2(x) \]
\[ \argmin_x \{\, \alpha_1 f_1(x) + \alpha_2 f_2(x)\} = \argmin_x \{\, f_1(x) + \tfrac{\alpha_2}{\alpha_1} f_2(x)\} \]
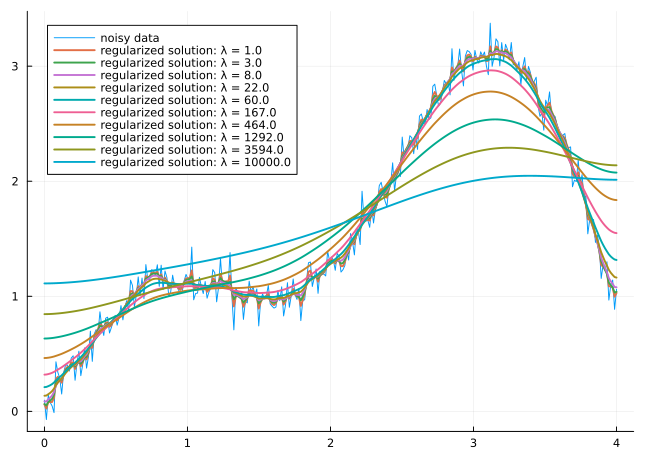
observe noisy measurements \(y\) of a signal \[ b = \hat x + \eta \textt{where} \left\{\begin{aligned} x^\natural&\in\Rn\ \text{is true signal} \\\eta &\in\R^n\ \text{is noise} \end{aligned} \right. \]
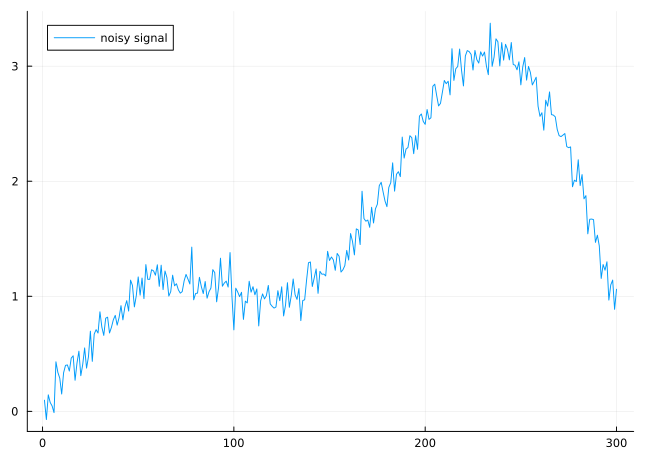
Naive least squares fits noise perfectly: \(b\) solves \(\min_x\|x - b\|^2\)
assumption: \(x^\natural\) is smooth \(\quad\Longrightarrow\quad\) balance fidelity to data against smoothness
\[ \min_x\ \underbrace{\|x - b\|^2}_{f_1(x)} +\underbrace{\lambda\sum_{i=1}^{n-1}\|x_i-x_{i+1}\|^2}_{f_2(x)} \]