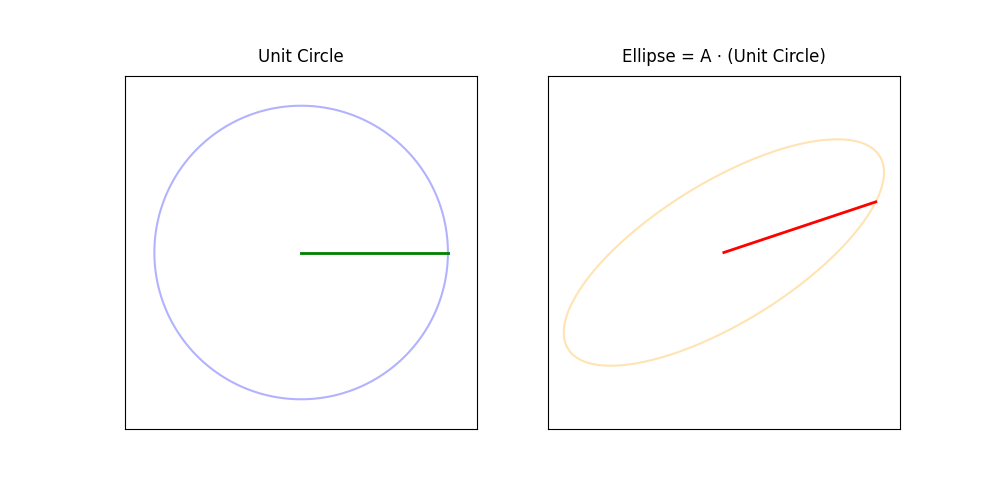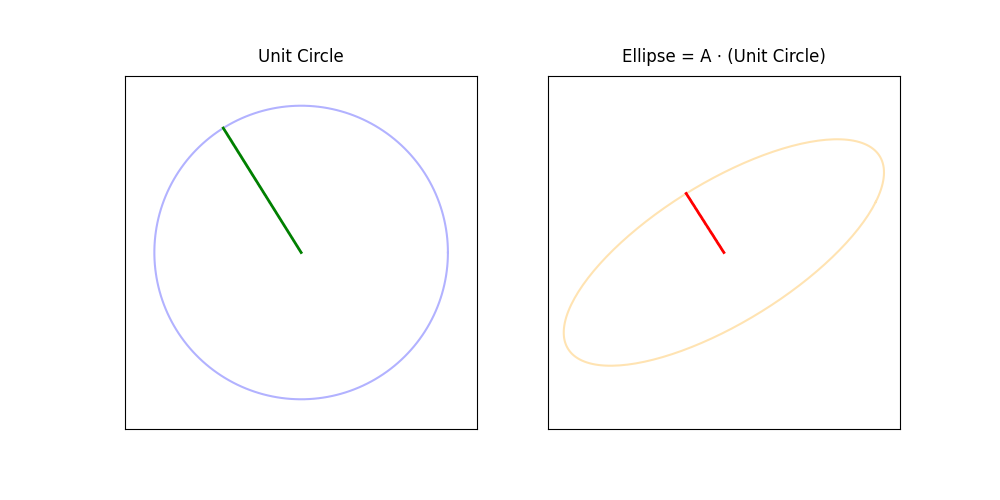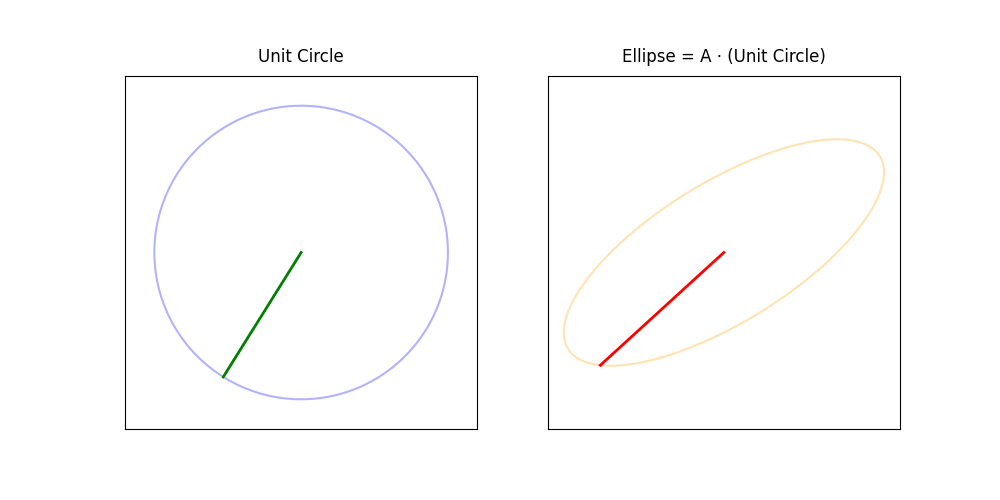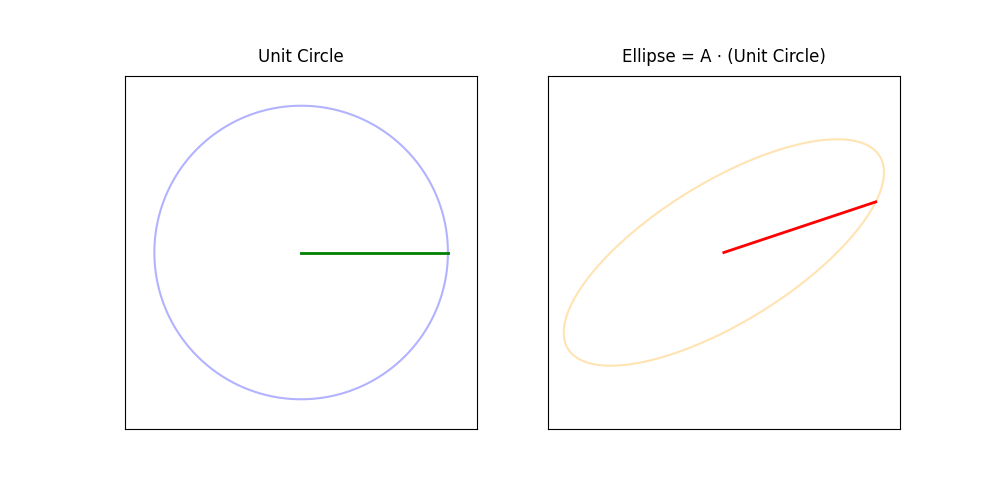
The singular value decomposition (SVD) reveals many of the most important properties of a matrix. It generalizes the eigenvalue decomposition to non-square matrices.
geometric interpretation
reduced SVD
full SVD
formal definition
Matrix Rank
The rank of a matrix \(A\) is the maximum number of linearly independent columns (or rows) of \(A\). It indicates the dimension of the subspace spanned by its columns (or rows).
Column rank is the dimension of the column space \(\range(A)\)
Row rank is the dimension of the row space \(\range(A^T)\)
Full rank if \(\rank(A) = \min(m,n)\)
for any matrix, the row and column rank are equal, so we just say rank
Conceptually, we can construct the SVD from the Grammian \(A^T A\):
gather the eigenvalues of \(A^T A\) in descending order (may be multiplicity): \[
\lambda_1\geq \lambda_2\geq \cdots \geq \lambda_r > 0,
\qquad
\Lambda := \mathbf{Diag}(\lambda_1,\ldots,\lambda_r)
\]
because \(A^T A\) is symmetric, the spectral theorem ensures it’s diagonalizable \[
A^T A = V\Lambda V^T
\]
Suppose that \(u\in\R^m\) and \(v\in\R^n\) are unit-norm vectors. Then the outer product \(uv^T\) is an \(m\times n\) matrix with rank 1. What is the spectral norm of \(uv^T\)?
\(\quad 1\)
\(\quad u^T v\)
\(\quad 2\)
\(\quad \|u\|_2 + \|v\|_2\)
Question: Spectral norm II
Suppose that \(x\in\R^m\) and \(y\in\R^n\) are nonzero vectors. Then the outer product \(xy^T\) is an \(m\times n\) matrix with rank 1. What is the spectral norm of \(xy^T\)?
The best rank-\(k\) approximation to \(A\) is given by rank-\(k\) approximation \[
A_k = \sum_{j=1}^k \sigma_j u_j v_j^T
\] with error \(E_k := A - A_k\) satisfying \[
\|E_k\|_2 = \sigma_{k+1}
\textt{and}
\|E_k\|_F = \sqrt{\sum_{j=k+1}^r \sigma_j^2}
\]
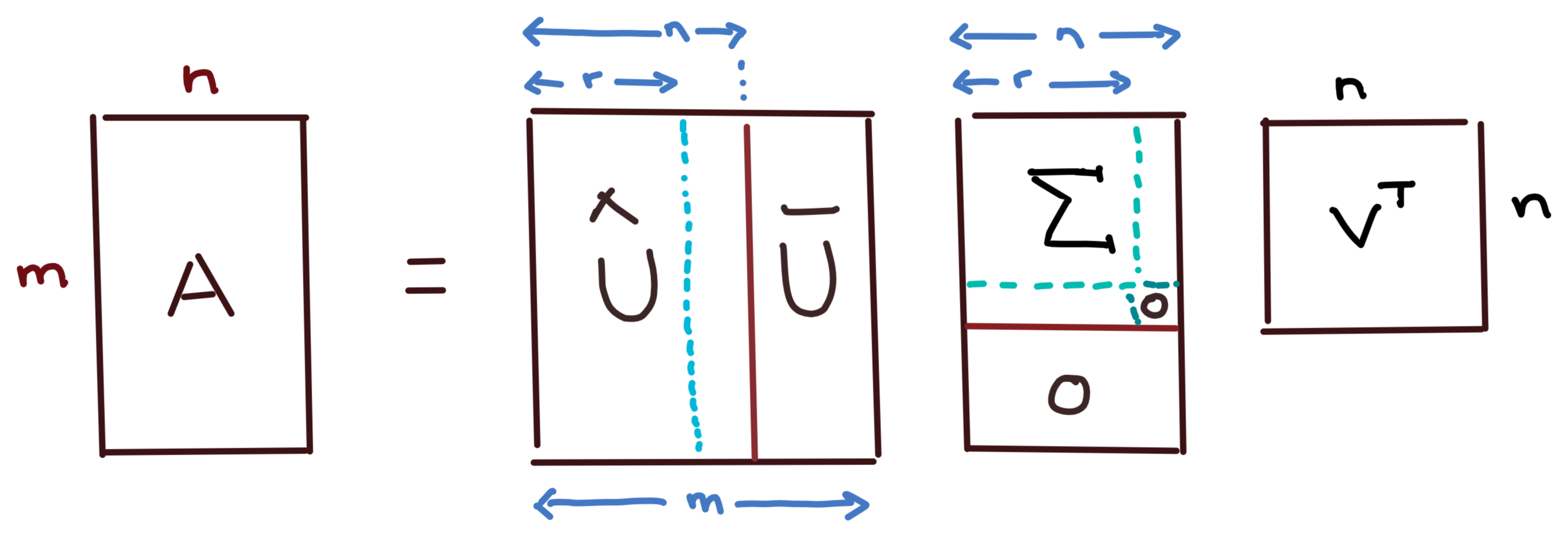
Full SVD
\[
\begin{aligned}
U &= [\,\hat U \mid \bar U\, ]\\
\hat U &= [\, u_1,\ldots,u_r, u_{r+1}, \ldots, u_n\, ]\\
\bar U &= [\, u_{n+1}, \ldots, u_m\, ]\\
V &= [\, v_1,\ldots,v_n\, ]\\
\Sigma &= \Diag(\sigma_1,\ldots,\sigma_r,0,\ldots,0)
\end{aligned}
\]
Provides orthogonal bases for all four fundamental subspaces
If \(A\) is \(m\times n\) with \(\rank(A)=r<n\), then infinitely many least-squares solutions: \[
\mathcal X = \{x\in\Rn \mid A^T A x = A^T b\}
\]
SVD provides the minimum norm solution \(\bar x = \min\{ \|x\| \mid x\in\mathcal X\}\)
If \(A=U\Sigma V^T\) is the full SVD of \(A\), then \[
\begin{aligned}
\|Ax-b\|^2 &= \|(U^T A V)(V^T x) - U^T b\|^2 \\
&= \|\Sigma y - U^T b\|^2 & (y:= V^T x)\\
&= \sum_{j=1}^r (\sigma_j y_j - \bar b_j)^2 + \sum_{j=r+1}^n \bar b_j^2 & (\bar b_j=u_j^T b)\\
\end{aligned}
\] Choose \[
y_j = \begin{cases}
\bar b_j/\sigma_j & j=1:r\\
0 & j=r+1:n
\end{cases}
\quad\Longrightarrow\quad
\bar x = V y = \sum_{j=1}^r \frac{u_j^T b}{\sigma_j} v_j
\]
Pseudoinverse of a Matrix
The pseudoinverse of a matrix \(A\), denoted \(A^+\), generalizes the inverse for matrices that may not be square or full rank. If \(A = U \Sigma V^T\) is the SVD of \(A\), then: \[
A^+ := V \Sigma^+ U^T \quad\text{where}\quad
\Sigma^+_{ij} =
\begin{cases}
1 / \sigma_i & \text{if } \sigma_i > 0 \\
0 & \text{if } \sigma_i = 0
\end{cases}
\]
Key Properties
\(A^+ A\) projects onto the column space of \(A\)
\(A A^+\) projects onto the row space of \(A^T\)
\(A^+\) always exists for any matrix \(A\), regardless of its shape or rank
Connection to the Minimum Norm Solution
The pseudoinverse provides the minimum norm least-squares solution to \(\|A x - b\|\): \[
\bar{x} = A^+ b
\]